最开始使用一张16G显存的Tesla T10显卡推理大模型,不满足于32B模型爆显存后速度极慢,于是又购入一张Tesla T10显卡,双卡32G显存,发现显存是叠加了,跑ollama的32B量化模型也不会爆显存了。
32B模型推理速度:
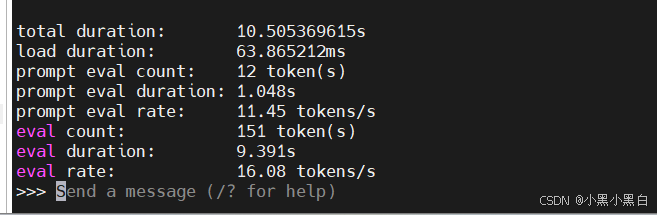
14B模型推理速度:
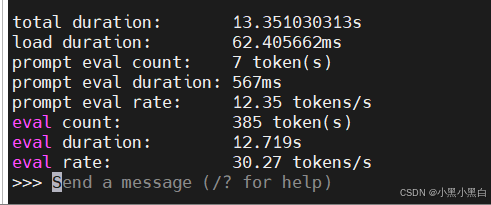
但推理速度相比之前未爆显存的速度没有明显叠加,看了下ollama不支持GPU张量并行,于是打算把ollama替换到vllm平台进行推理。
但研究了发现由于vllm是预分配显存,–gpu_memory_utilization参数设置比例,待机会占用不少显存,没跑推理时显卡待机功耗就比较高,实测T10显卡每张卡大概50几W功耗,而ollama的OLLAMA_KEEP_ALIVE默认是5分钟空闲会释放模型显存,还能自定义时间,到一定时间未调用推理,会主动释放,释放显存后显卡待机功耗每张10W左右(如下图)。
ollama主动释放后GPU待机:
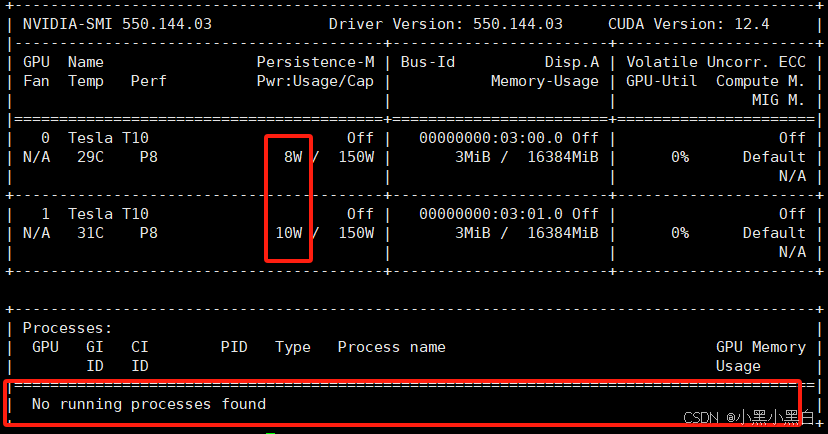
vllm预占用显存下GPU待机:
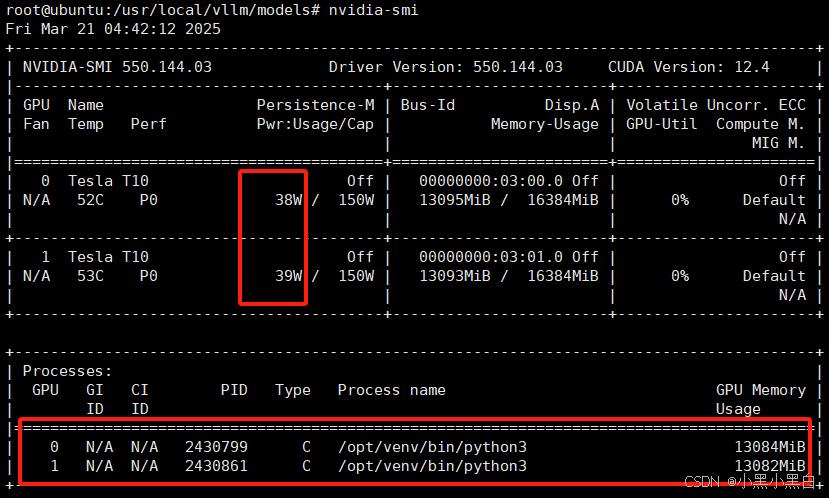
相当于用vllm两张卡每小时共多60W的能耗,待机情况下,一天大概比ollama多1点几度电。而vllm强在多线程并行推理性能很强,可以说并行推理秒杀ollama,实测推理时GPU占用都是很高的,但如果不并行使用的话,推理速度与ollama差不多,个人家用的话,考虑到能耗问题,不建议使用vllm,但如果是公司用的话还是强烈建议vllm的。
vllm相关脚本自记录:
镜像加速拉取:docker pull docker.1ms.run/vllm/vllm-openai:latest
创建vllm文件夹,并创建models子文件夹存放模型文件
自行下载模型文件到models文件夹下(如ModelCloud/QwQ-32B-gptqmodel-4bit-vortex-v1)。
docker-compose.yaml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| services:
vllm:
container_name: vllm-server
restart: no
image: docker.1ms.run/vllm/vllm-openai:latest
ipc: host
volumes:
- ./models:/models
command: ["--model", "/models/QwQ-32B-gptqmodel-4bit-vortex-v1", "--max-model-len", "8192", "--served-model-name", "qwq-32b-q4", "--gpu-memory-utilization", "0.85", "--tensor-parallel-size", "2", "--max-num-seqs", "2", "--dtype", "half"]
ports:
- 8006:8000
environment:
- 'HUGGING_FACE_HUB_TOKEN=Hugging Face的Access Tokens'
- 'HF_ENDPOINT=https://hf-mirror.com'
- 'VLLM_API_KEY=vllm666'
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
|
验证请求:
1
2
3
4
5
6
7
8
9
10
| //验证请求
curl http://192.168.31.8:8006/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer vllm666" \//密码
-d '{
"model": "QwQ-32B",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
|