本文主要描述在TrueNas Scale中,为Immich应用配置GPU硬件加速的踩坑记录,旨在加速immich的人脸识别,ocr识别等智能模型推理,欢迎沟通讨论~
前言
自从TrueNas Scale从Electric Eel 24.10.1版本由k3s转docker之后,对于容器镜像的操作更加方便,immich的快速迭代与truenas scale的兼容适配也更好,之前immich导入本地模型,pod重启消失的问题也优化了。随着最近immich的OCR文本识别的功能集成,针对历史图片的机器学习识别任务变得十分耗时,于是想着将原本靠CPU跑的机器学习,转到GPU上从而实现硬件加速。
集成GPU
在 TrueNAS SCALE 上为应用启用 NVIDIA GPU:
验证 GPU 检测:
通过运行lspci | grep NVIDIA确保 TrueNAS 看到了你的 NVIDIA 显卡。为 Docker 启用 NVIDIA:
使用以下命令配置 Docker 使用 NVIDIA 运行时:
midclt call -j docker.update '{"nvidia": true}'重启 TrueNAS:
重启 TrueNAS 系统以应用 Docker 更改。验证 Docker NVIDIA 运行时:
通过运行docker info | grep -i nvidia确认 Docker 配置正确。你应该看到 nvidia 列在 Runtimes 中,并且是默认运行时。
识别 GPU UUID: 使用 nvidia-smi -L 获取 NVIDIA GPU 的 UUID。
1 | GPU 0: Tesla T10 (UUID: GPU-2fa76313-8ba3-088c-96ce-150593b6d036) |
5. 编辑immich,勾选列表的GPU启动即可
如果GPU名称是null,或者不展示GPU或者启动报错往下继续操作
使用 UUID 更新应用程序配置:
对于每个需要 GPU 访问的应用程序,使用 midclt call app.update 命令显式链接应用程序资源中的 GPU PCI 插槽和 UUID。将如下 0000:03:00.0替换为对应nvidia-smi输出面板中的值、uuid(GPU-2fa76313-8ba3-088c-96ce-150593b6d036) 替换为nvidia-smi -L中输出的uuid值
例:
1 | midclt call -j app.update immich '{"values": {"resources": {"gpus": {"use_all_gpus": false, "nvidia_gpu_selection": {"0000:03:00.0": {"use_gpu": true, "uuid": "GPU-2fa76313-8ba3-088c-96ce-150593b6d036"}}}}}}' |
更新immich应用配置,勾选对应GPU,重启immich应用程序。
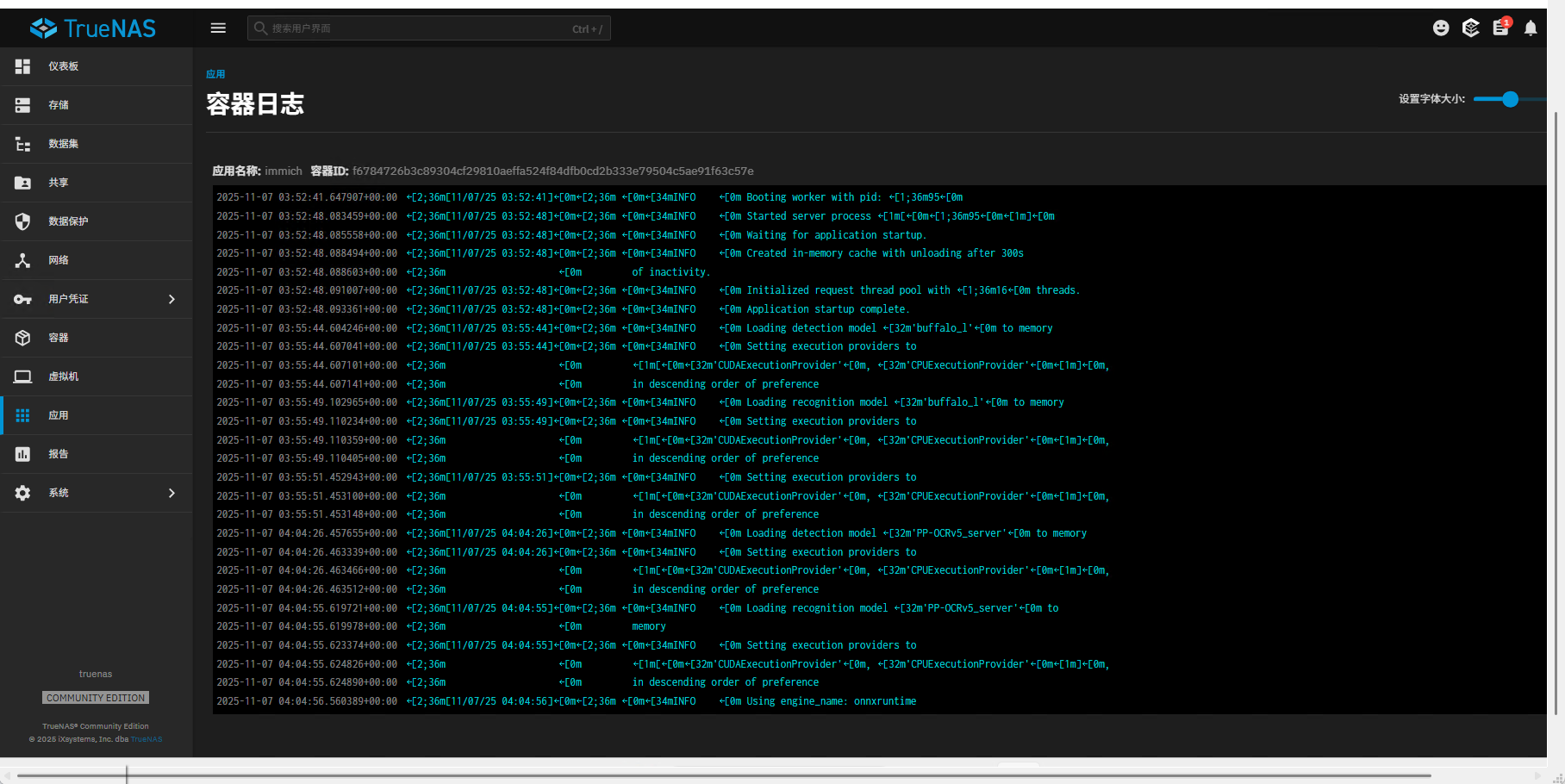
重启后运行机器学习任务,查看GPU: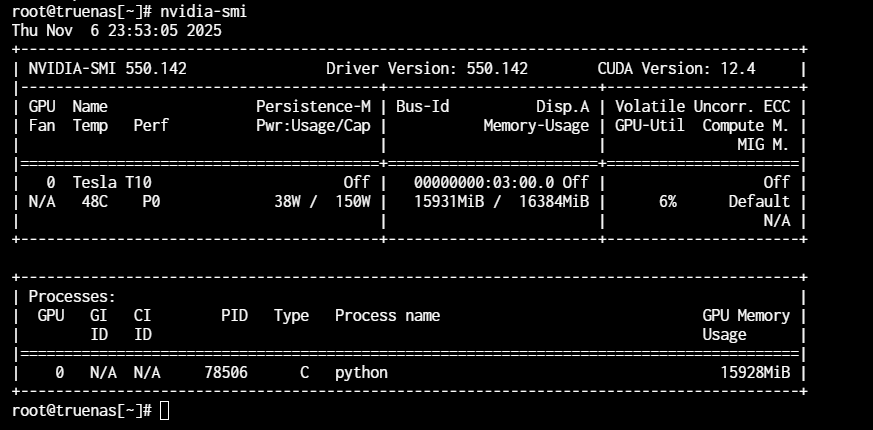
机器学习任务日志输出: